' fill='none' stroke='%23304560' stroke-miterlimit='10' stroke-width='2'/%3e%3c/svg%3e)

Precision, power, performance: the power of blocking in statistical experiments
The VSNi Team
13 July 2021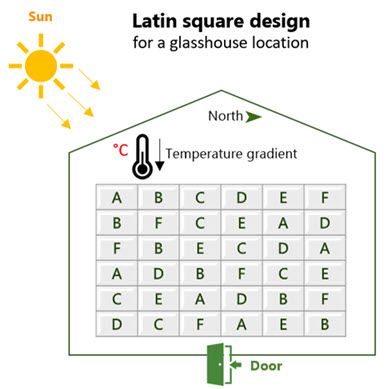
When conducting an experiment, an important consideration is how to even out the variability among the experimental units to make comparisons between the treatments fair and precise. Ideally, we should try to minimize the variability by carefully controlling the conditions under which we conduct the experiment. However, there are many situations where the experimental units are non-uniform. For example:
- in a field experiment laid out on a slope, the plots at the bottom of the slope may be more fertile than the plots at the top,
- in a medical trial, the weight and age of subjects may vary.
When you know there are differences between the experimental units (and these differences may potentially affect your response), you can improve precision and avoid bias by blocking. Blocking involves grouping the experimental units into more-or-less homogeneous groups, so that the experimental units within each block are as alike as possible. For example, in the field experiment described above, plots would be blocked (i.e., grouped) according to slope, and in medical trial, subjects would be blocked into groups of similar weight and age. Once the blocks are formed, the treatments are then randomized to the experimental units within each block.
| Blocking is used to control nuisance variation by creating homogeneous groups of experimental units, known as blocks. |
Blocking can improve precision
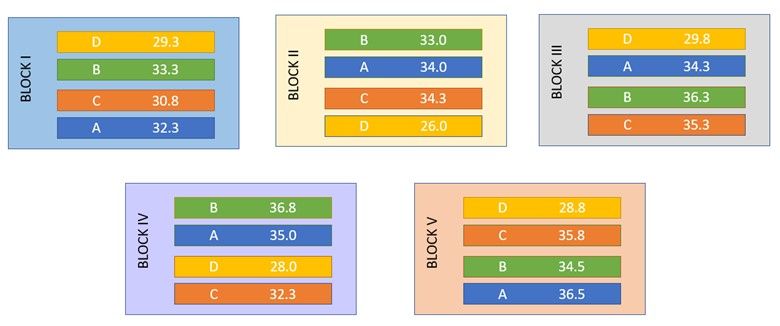
Let’s look at an example[1] to see how blocking improves the precision of an experiment by reducing the unexplained variation. In this field trial, the yields (pounds per plot) of four strains of Gallipoli wheat were studied. During the design phase, the 20 experimental plots were grouped into five blocks (each containing 4 plots). Within each block, the four wheat strains (A, B, C and D) were randomly assigned to the plots. This is an example of a randomized complete block design (RCBD).
In randomized complete block design (RCBD)…
|
To demonstrate the advantage of blocking, we’ll analyse the data in Genstat[2]as both a completely randomized design (CRD, which ignores the blocking), and as a RCBD (which takes the blocking into account). One of the assumptions behind a CRD is that the set of experimental units to which the treatments are applied are effectively homogeneous.
CRD | RCBD |
 |  |
CRD |
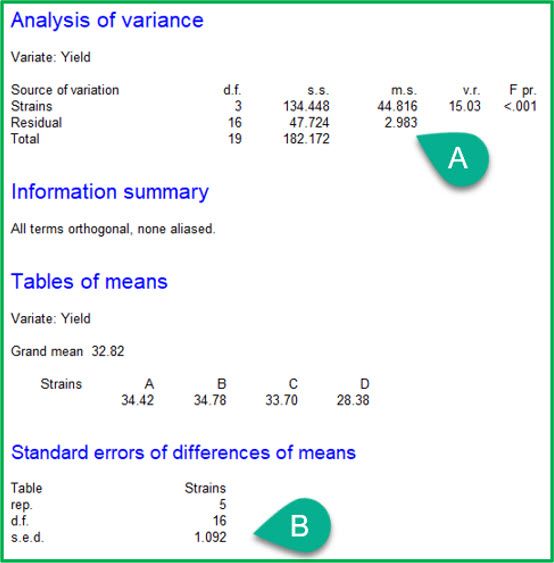 |
RCBD |
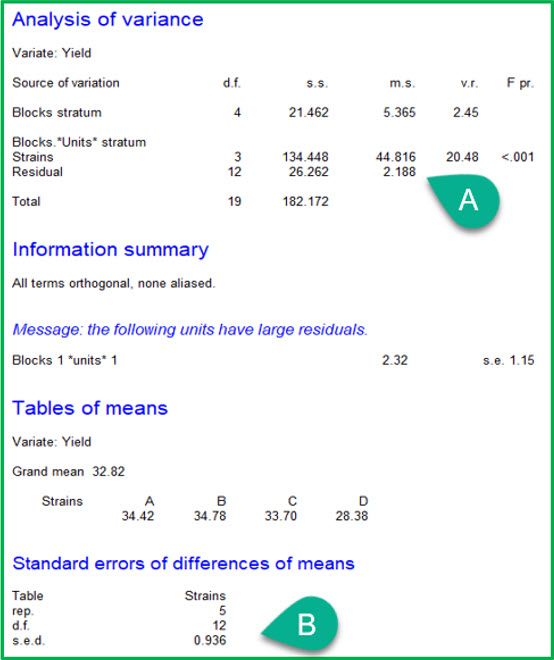 |
The ANOVA tables from the two analyses are given above. Notice that the ANOVA table for the RCBD has an additional line, “Blocks stratum”. This records the variation between blocks. Also note that the treatment effects (i.e., strains) are now estimated in the “Blocks.*Units* stratum”, which represents the variation within blocks. As a result:
A: the residual mean square (i.e., the unexplained variation) has decreased from 2.983 to 2.188
B: the standard error of the difference (s.e.d.) has decreased from 1.092 to 0.936.
That is, blocking has improved the precision of the experiment! This increase in precision means that we have a better chance of detecting differences between the wheat strains, making this experiment more efficient and with increased statistical power.
| If you suspect that certain groups of experimental units may differ from each other, you can always use those groups as a blocking factor. If the differences do appear, your estimated treatment effects will be more precise than if you had not included blocking in the statistical model. |
Blocking can protect against bias
Let’s look at an example to see blocking how can guard against bias by evening out the variability among experimental units.
Imagine you want to test a new manufacturing process at your factory by measuring levels of daily productivity over four weeks. However, experience tells you that production levels tend to be lower on Thursdays and Fridays, compared to earlier on in the week as employees’ thoughts turn to going home for the weekend. Let’s consider what might happen should you simply randomly select 10 days to use the old manufacturing process and 10 days to use the new. The following table represents one possible randomization:
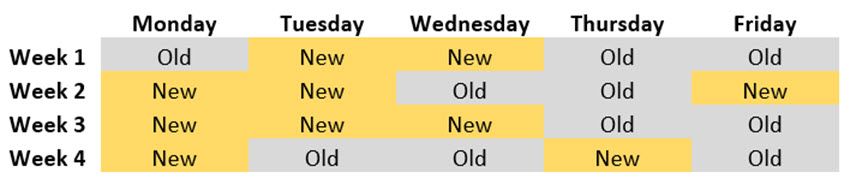
Notice that by not controlling for day of the week, the new manufacturing process is (randomly) over-represented on days where production naturally tends to be higher, whereas the old manufacturing process is (randomly) over-represented on Thursdays and Fridays, where production naturally tends to be lower, resulting in an unfair comparison.
Conversely, had you blocked by day of the week, then the inherent differences between days is evened out and the bias it can potentially cause is no longer an issue. For example, we can have a randomization like:
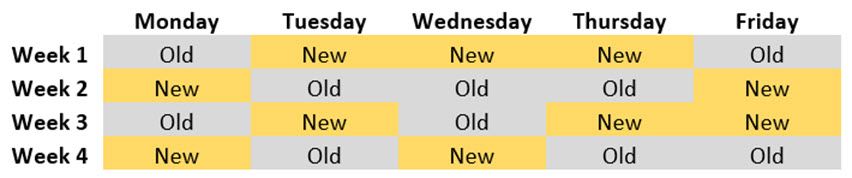
Note that every treatment (manufacturing process) occurs the same number of times every day. That is, we have a balanced experiment that controls for bias due to day difference. Hence, any resulting production increase or decrease can be more confidently attributed to the manufacturing process used.
As shown above, blocking and randomization are critical aspects of good experimental design, providing us with increased precision and protection against bias.
| You can learn more about blocking and experimental design in Genstat by watching this short YouTube video: Experimental design in Genstat |
[1] Snedecor, G.W. (1946). Statistical methods. The Iowa State College Press, Ames, Iowa, USA.
[2] This data set can be accessed from within Genstat. From the menu select File | Open Example Data Sets then type “Wheatstrains.gsh” and click Open.
Popular



Related Reads